
Overflowing the Tier 2

The expected wait time for some of these users (55 active users) is over a month. There are a few questions that arise from this situation:
- Why are so many people submitting here?
- How can we help users get science done faster?
The second question is the fun one. To answer this question, we decided to flock jobs to Purdue through our GlideinWMS frontend.
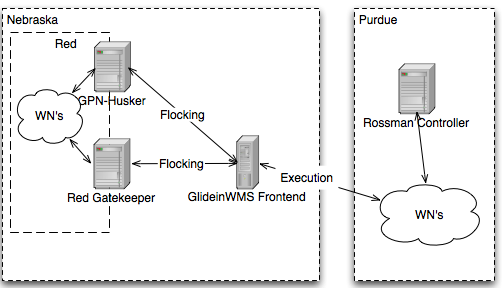
Here's a diagram of our idea.

- The Red gatekeepers will advertise idle jobs to the HCC GlideinWMS Frontend.
- The frontend will ask for glideins at the Purdue CMS clusters, submitting with a CMS certificate.
- When the glideins report back, the Frontend will negotiate with Red's gatekeepers to send jobs to the glideins at Purdue.
- Once at Purdue, the CMS analysis jobs will use Purdue's CMS software install, and XRootd to stream data from UNL.
GlideinWMS Configuration
The GlideinWMS Frontend needed to add another group that would query the red gatekeepers. We named this group T2Overflow.
The glideins that start as a part of the T2Overflow group will only run jobs from the T2. We accomplished this with a new start expression in the glideins:
<attr name="GLIDECLIENT_Group_Start" glidein_publish="False" job_publish="False" parameter="True" type="string" value="(TARGET.IsT2Overflow =?= TRUE)"></attr>
Next, we want the glideins to be submitted as the CMS user, since they are CMS jobs. For this, we used Brian's certificate. We changed how we specify the proxy used to submit, from globally at the top of the frontend.xml file, to per group. If it is defined both places, the frontend/factory will round-robin between the proxies.
Next, we want to submit to the Purdue CMS cluster, this required changing our entry point match expression to:
<factory query_expr="(GLIDEIN_Site == "Purdue")&&((stringListMember("CMS", GLIDEIN_Supported_VOs)))"></factory>
Gatekeeper Configuration
The jobs that will flock to Purdue are limited by the glideins START expression listed above. Now, we want the jobs to only flock to the T2Overflow group, not other groups running on the HCC Frontend. In order to do this, we needed to change the requirements of the jobs and inside the condor.pm to include:
( IS_GLIDEIN =!= true || TARGET.GLIDECLIENT_Group =?= "T2Overflow" )
This tells Condor: If we're matching to a glidein (IS_GLIDEIN = true), then only match to the T2Overflow group.
The jobs need the IsT2Overflow = true in order for the frontend to pick up the idle jobs. The IsT2Overflow attribute is also used in the START expression on the glideins to only start overflow jobs. This attribute was added to each job in the condor.pm using the condor syntax:
+IsT2Overflow = false
This way, jobs are automatically disabled from overflowing, but can be easily changed by doing a condor_qedit.
Also for the jobs, we need to configure the environment. When a globus job is submitted to Condor, the Environment classad is filled with site specific attributes. When we flock to Purdue, we want to erase those attributes and instead use the ones given to us from the glidein environment.
The environment changing proved difficult. Our goal is to use an expression such as:
Env = $$([ ifThenElse(WantsT2Overflow=?=true, "", "MyEnv=yes") ])
In our testing, the environment ended up empty in both the True and False cases.
UPDATE: 4/29 9:30AM
We figured out the error with the environment, and opened a Condor ticket. In the mean time, we figured out a work around:
Environment = "$$([ ifThenElse(IsT2Overflow =?= TRUE, \"IsT2Overflow=1\", \"...\") ])"
Where the ... is the original environment. This will cause the environment to stay the same if the job is executed on the Nebraska T2, but to wipe out the environment if executed on in the Overflow nodes.
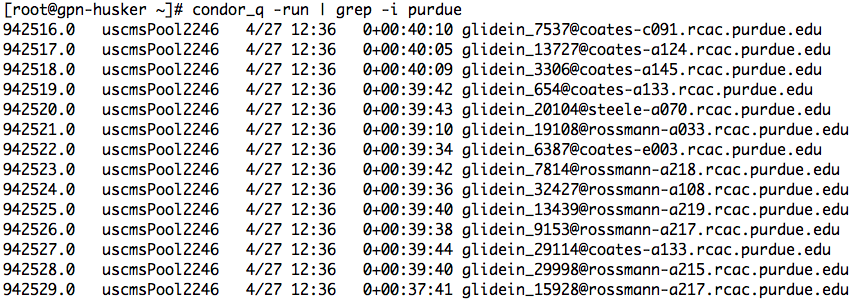
We have the Overflow working for ~500 jobs now.

{kind=link}
Leave a comment