
HTCondor-CE-Bosco Upcoming Release
The HTCondor-CE-Bosco (CE-Bosco) is one of the largest changes for the upcoming OSG 3.3.12 release, to be released on 2016/05/10. The HTCondor-CE-Bosco is a special configuration of the HTCondor-CE. The HTCondor-CE-Bosco does not submit directly to a local scheduler such as Slurm or PBS, instead, it will submit jobs to a remote cluster over SSH.
The HTCondor-CE-Bosco is designed to make it easier to contribute opportunistic resources to the OSG. Instead of allocating a special node or VM that can run services as root, and submit to the local cluster to run an OSG CE. With the HTCondor-CE-Bosco, an organization can setup a separate node with only SSH access to the cluster. In addition, the OSG can host and manage the CE for an opportunistic resource, reducing the load on the admins completely.
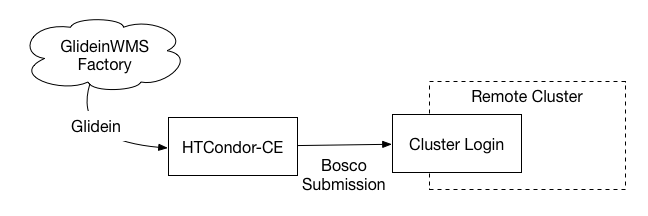
The HTCondor-CE portion acts just like any other CE. It can authenticate with GUMS, or use simple grid-mapfile. It runs the normal HTCondor-CE daemons such as the Collector and Schedd. But, there is a special route that instructs the HTCondor-CE to submit to a remote resource rather than a local scheduler.
JOB_ROUTER_ENTRIES = \
[ \
GridResource = "batch condor [email protected]"; \
TargetUniverse = 9; \
name = "Local_BOSCO"; \
]
This route tells the HTCondor-CE to transform the incoming job into a Bosco job to be submitted to a remote cluster. The above code snippet is from my development testbed.
The configuration of a HTCondor-CE-Bosco is minimal beyond a normal HTCondor-CE. All that is required is:
- An ssh key to the remote cluster for password-less ssh.
- What kind of Batch system is installed on the remote cluster, for example, Slurm, PBS, LSF…
Full installation instructions are OSG’s Twiki. Configuration of the HTCondor-CE-Bosco is managed by the osg-configure tool and an ini file in /etc/osg/config.d/20-bosco.ini.
Accounting
A new probe called the HTCondor-CE probe is used to collect usage information for the HTCondor-CE-Bosco. Instead of querying the Slurm or PBS scheduler for completed job information, it uses HTCondor’s accounting information to create records. In this way, it is generic and can be used for all HTCondor-CE’s without setting up special logging directories like in the PBS probe, or requiring access to a MySQL DB like the Slurm probe.
The HTCondor-CE probe is a copy of the regular HTCondor probe, but looks configures the HTCondor-CE to output PER_JOB_HISTORY records into the Gratia probe’s data directory. Additionally, since the HTCondor-CE-Bosco creates two jobs for every one job that is submitted, the probe must filter and ignore one of the job records. The new probe checks for the RoutedToJobId attribute in the job’s ClassAd. If it exists, the job is classified as a Local job since it is not actually run, and is later discarded since the configuration sets SuppressGridLocalRecords to 1.
Future Directions
The HTCondor-CE-Bosco opens possibilities in the future as well. For example, you could add multiple Bosco endpoints for which a CE could submit. Either these could be configured as separate endpoints or the HTCondor JobRouter could round-robin submissions to the Bosco clusters. This could allow for load balancing between the different clusters with the proper PERIODIC_HOLD and PERIODIC_RELEASE options are configured.
The new router configuration for multiple Bosco endpoints would look like:
JOB_ROUTER_ENTRIES = \
[ \
GridResource = "batch condor [email protected]"; \
TargetUniverse = 9; \
name = "Local_BOSCO"; \
] \
[ \
GridResource = "batch condor [email protected]"; \
TargetUniverse = 9; \
name = "Local_BOSCO_nebraska"; \
]
In this configuration, the JobRouter would round-robin between both of the Bosco entry points.
Some Conclusions
The HTCondor-CE-Bosco provides a great starting point for opportunistic resource owners that want to contribute to the OSG. It is easy to setup, and requires minimal resources on the part of the cluster since it simply submits jobs through a SSH connection.
Decisions, Decisions
The HTCondor-CE and the CE-Bosco have pros and cons for usage. For example, the HTCondor-CE is designed to scale to thousands of submitted jobs, while the CE-Bosco has not yet been optimized for that use case. Instead, we have focused on the user friendliness of the CE-Bosco rather than the regular HTCondor-CE. Listed below is a list of features of the HTCondor-CE and the CE-Bosco.
| Features (more to be added) | HTCondor-CE | CE-Bosco |
|---|---|---|
| Scales to >1000s of jobs | ✅ | ❌ |
| No special cluster submit node | ❌ | ✅ |
| No special scheduler configuration | ❌ | ✅ |
It’s difficult to summarize which solution you should choose for your site, the HTCondor-CE or CE-Bosco. Each site and cluster has it’s own special requirements. If you are hesitant to modify your cluster for grid jobs, for example adding a new submit node and exporting read access to the Slurm Database, then CE-Bosco is your best choice. If you are willing to make the adjustments to your cluster above, then your cluster can scale to thousands of running grid jobs.
If you are a site that is interested in a HTCondor-CE-Bosco hosted by the OSG, contact OSG User Support. This can significantly reduce the administrative effort required for a site to join the OSG.

Leave a comment