HCC Walltime Effeciency

What's interesting is that we rarely run jobs at RENCI-Engagement, OSCER, or GPGRID. It's difficult to interpret this. Since we run so many workflows, it's not clear to me that this means much.

The XRootD Monitoring Collector (collector) receives file transfer accounting messages from XRootD servers. This transfer information is parsed by the collec...
Creating dashboards and data visualizations are a favorite past time of mine. Also, I jump at any chance to learn a new technology. That is why I have spen...
Optimizing data transfers requires tuning many parameters. High latency between the client and a server can decrease data transfer throughput. The Open Scie...
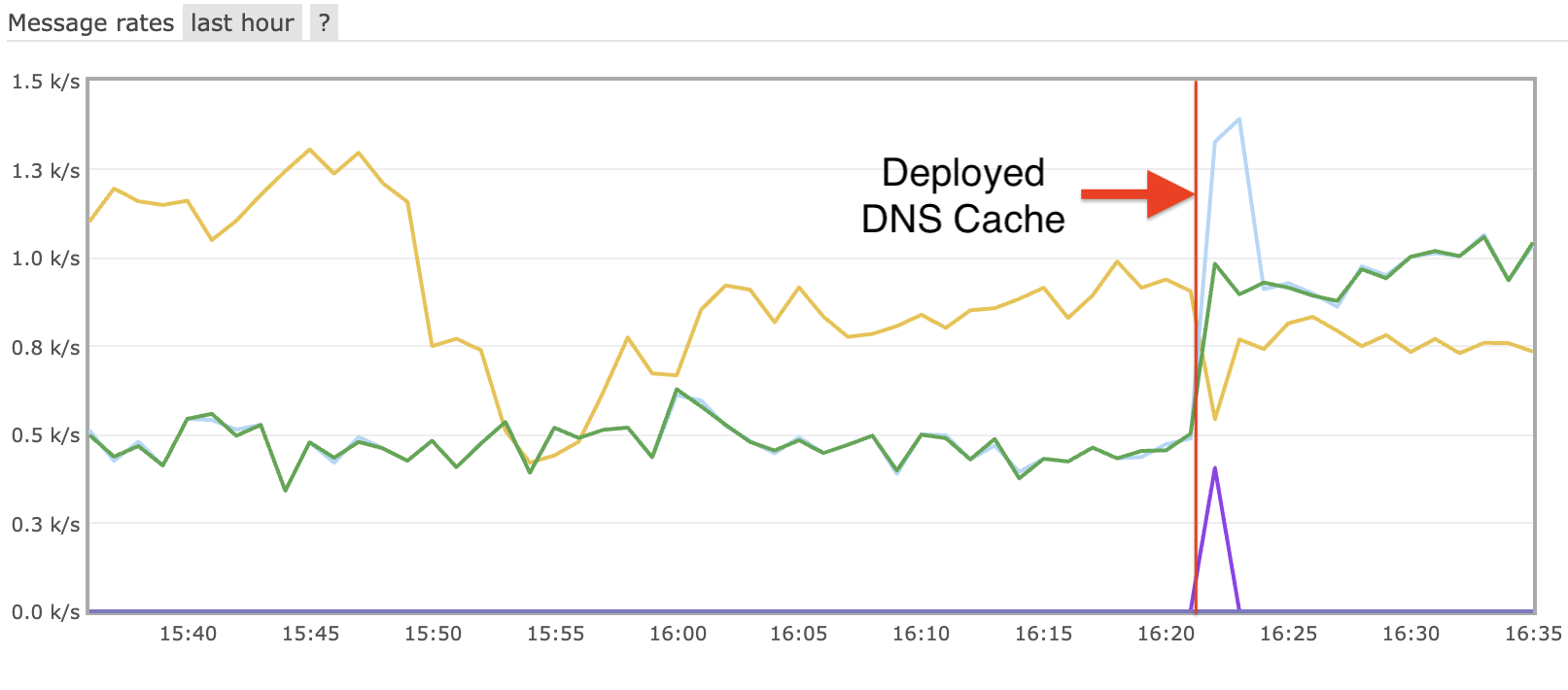
The validation project for XRootD Monitoring is moving to phase 2, scale testing. Phase 1 focused on correctness of single server monitoring. The report is...

Leave a comment