January 25, 2015
HTCondor CacheD: Caching for HTC - Part 2
In the previous post, I discussed why we decided to make the HTCondor CacheD. This time, we will discuss the operation and design of the CacheD, as well as show an example utilizing a BLAST database.It is important to note that the CacheD is still very much “dissertation-ware.” It functions enough to demonstrate the improvements, but not enough to be put into production.<h4>The Cache</h4><div>The fundamental unit that the CacheD works with is an immutable set of files in a cache. A user creates and uploads files into the cache. Once the upload is complete, the cache is committed and may not be altered at any time. The cache has a set of metadata associated with it as well, stored as classads in a durable storage database (using the same techniques as the SchedD job queue).</div><div></div><div>The cache has a ‘lease’, or an expiration date. This lease is a given amount of time that the cache is guaranteed to be available from a particular CacheD. When creating the cache, the user provides a requested cache lifetime. The CacheD can either accept or reject the requested cache lifetime. Once the cache’s lifetime expires, it can be deleted by the CacheD and is no longer guaranteed to be available. The user may request to extend the lifetime of a cache after it has already been committed, which the CacheD may or may not accept.</div><div></div><div>The cache also has properties similar to a job. For example, the cache can have it’s own set of requirements for which nodes it can be replicated to. By default, a cache is initialized with the requirement that a CacheD has enough disk space to hold the cache. Analogous to the HTCondor matching with jobs, the cache can have requirements, and the CacheD can have requirements. A CacheD requirements may be that the node has enough disk space to hold the matched cache. This two way matching guarantees that any local policies are enforced.</div><div></div><div>The requirements attribute is especially useful when the user aligns the cache’s requirements with the jobs that require the data. For example, if the user knows that their processing requires nodes with 8GB of ram available, then there is no point is replicating the cache to a node with less than 8GB of ram.</div><div></div><h4>The CacheD</h4><div>The CacheD is the daemon that manages caches on the local node. Each CacheD is considered a peer to all other CacheD’s, there is no further coordination daemon. Each cache serves multiple functions:</div><div><ol><li>Respond to user requests to create, query, update, and delete caches.</li><li>Send replication requests to CacheD’s that match each cache’s requirements.</li><li>Respond to replication requests from other CacheD’s. Matching is done on the cache before transferring the data</li></ol><div>The CacheD keeps a database storing the metadata for each cache. The database is stored using the same techniques as the SchedD uses for jobs to maintain a durable database store. It also maintains a directory containing all of the caches stored on the node.</div></div><div></div><div>The CacheD’s user interface is primarily through python bindings, at least for the time being.</div><div></div><h4>CacheD Usage</h4><div>The CacheD is used in conjunction with glideins. The CacheD is started along with other glidein daemons such as the HTCondor StartD.</div><table align="center" cellpadding="0" cellspacing="0" class="tr-caption-container" style="margin-left: auto; margin-right: auto; text-align: center;"><tbody><tr><td style="text-align: center;"></td></tr><tr><td class="tr-caption" style="text-align: center;">Initialization of cache as well as initial replication requests</td></tr></tbody></table><div>The user initializes the cache by creating and uploading it to the user’s submit machine. The CacheD connects to remote CacheD’s, sending replication requests.</div><div class="separator" style="clear: both; text-align: center;"></div><div></div><table align="center" cellpadding="0" cellspacing="0" class="tr-caption-container" style="margin-left: auto; margin-right: auto; text-align: center;"><tbody><tr><td style="text-align: center;"></td></tr><tr><td class="tr-caption" style="text-align: center;">The BitTorrent communication between nodes after accepting the replication request</td></tr></tbody></table><div>Once the CacheD’s accept the replication request(s), BitTorrent protocol allows for communication between all nodes inside the cluster, as well with the user’s submit machine. This graph only shows a single cluster, but this could be replicated to many clusters as well.</div><div></div><h4>In Action </h4><table align="center" cellpadding="0" cellspacing="0" class="tr-caption-container" style="margin-left: auto; margin-right: auto; text-align: center;"><tbody><tr><td style="text-align: center;"></td></tr><tr><td class="tr-caption" style="text-align: center;">Partial graph showing data transfers. Due to overflowing the event queue, not all downloads are captured.</td></tr></tbody></table><div>The above graph shows the data transfer using the BitTorrent protocol between the nodes that have accepted the replication request and the Cache Origin, which is an external node. In this example, only 5 remote CacheD’s where started on the cluster. Because of all of the traffic between nodes, this level of detail graph becomes unreadable very quickly when increasing the number of remote CacheD’s.</div><div></div><div>You will notice that the Cache Origin only transfers to 2 nodes inside the cluster. The BitTorrent protocol is complicated and difficult to predict, therefore this could be caused by many factors. For example, the two nodes could have found the CacheD origin first, therefore being the first nodes to download it. The other nodes would then have found the internal cluster nodes with portions of the cache, and begun to download from it.It is important to note that even though the ~15GB cache is transferred to all 5 nodes, totalling 75GB of transferred cache, only ~15Gb is transferred from the cache origin, and all of the rest of the transfers are between nodes in the cluster.<h4>Up Next</h4></div><div>In Part 3 of the series, I will look at timings of the transfers using data analysis of trial runs. As a hint, the BitTorrent protocol is slower than direct transfers for 1 to 1 transfers. But it really shines when increasing the number of downloaders and seeders.</div><div></div>
It is important to note that the CacheD is still very much "dissertation-ware." It functions enough to demonstrate the improvements, but not enough to be put into production.
The Cache
The CacheD
- Respond to user requests to create, query, update, and delete caches.
- Send replication requests to CacheD's that match each cache's requirements.
- Respond to replication requests from other CacheD's. Matching is done on the cache before transferring the data
CacheD Usage
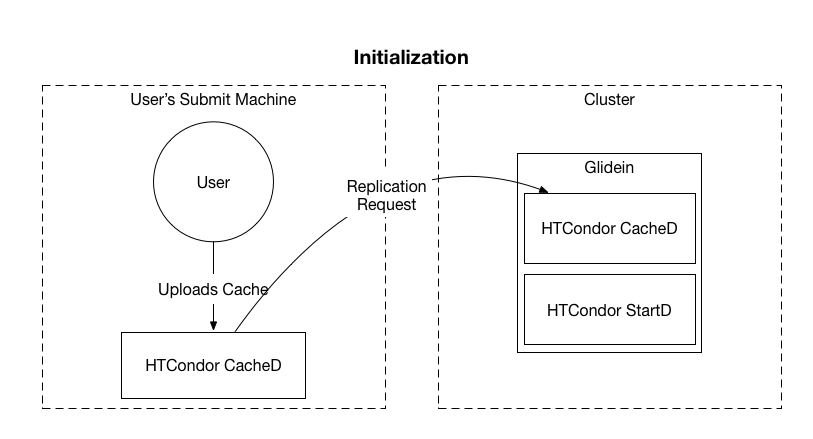 |
| Initialization of cache as well as initial replication requests |
 |
| The BitTorrent communication between nodes after accepting the replication request |
In Action
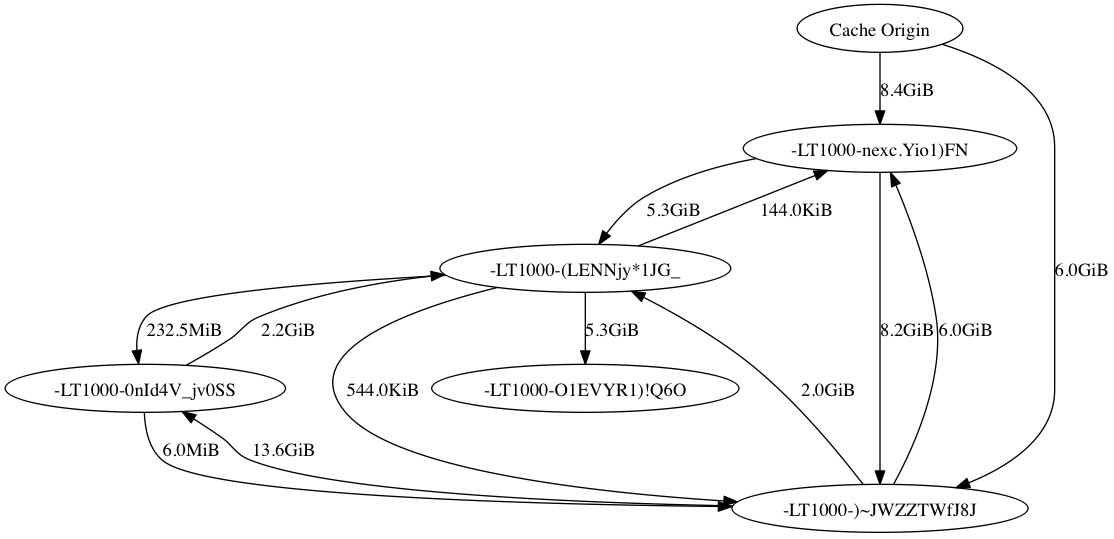 |
| Partial graph showing data transfers. Due to overflowing the event queue, not all downloads are captured. |
It is important to note that even though the ~15GB cache is transferred to all 5 nodes, totalling 75GB of transferred cache, only ~15Gb is transferred from the cache origin, and all of the rest of the transfers are between nodes in the cluster.