April 2, 2013
Reprocessing CMS events with Bosco
Prior to the LHC long shutdown, the CMS experiment increased the trigger rate of the detector, therefore increasing the data coming off the detector. The Tier-0 was unable to process all of the events coming off of the detector, therefore the events where only stored and not processed. After the run, the experiment wanted to process the backlog of events, but didn’t have the computing power available to do it. So they turned to opportunistic computing and Bosco.The CMS collaborators at UCSD worked with the San Diego Supercomputing Resource to run the processing on the Gordon supercomputer. Gordon is an XSEDE resource and does not include a traditional OSG Globus Gatekeeper. Also, we did not have root access to the cluster to install a gatekeeper. Therefore, Bosco was used to submit and manage the GlidienWMS Condor glideins to the resource.<table align="center" cellpadding="0" cellspacing="0" class="tr-caption-container" style="margin-left: auto; margin-right: auto; text-align: center;"><tbody><tr><td></td></tr><tr><td class="tr-caption" style="font-size: 13px;">Running jobs at Gordon, the SDSC supercomputer</td></tr></tbody></table>As you can see from the graph, we reached nearly 4,000 CMS processing jobs on Gordon. 4k cores is larger than most CMS Tier 2’s, and as big as a European Tier-1. With Bosco, overnight, Gordon became one of the largest CMS clusters in the world.Full details will be written in a submitted paper to CHEP ‘13 in Amsterdam, and Bosco will be presented in a poster (and paper) as well. I hope to see you there!(If I got any details wrong about the CMS side of this run, please let me know. I have intimate knowledge of the Gordon side, but not so much the CMS side).
Tags: bosco campus condor GlideinWMS osg
The CMS collaborators at UCSD worked with the San Diego Supercomputing Resource to run the processing on the Gordon supercomputer. Gordon is an XSEDE resource and does not include a traditional OSG Globus Gatekeeper. Also, we did not have root access to the cluster to install a gatekeeper. Therefore, Bosco was used to submit and manage the GlidienWMS Condor glideins to the resource.
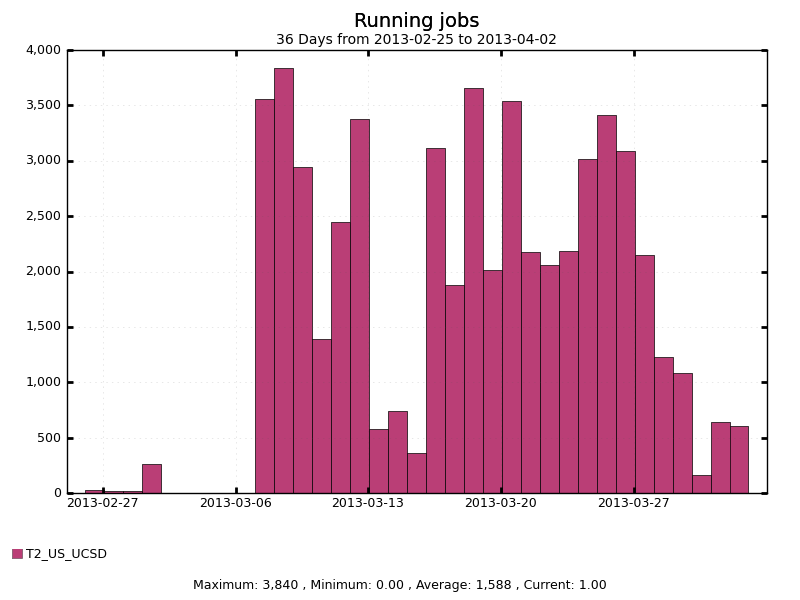 |
| Running jobs at Gordon, the SDSC supercomputer |
As you can see from the graph, we reached nearly 4,000 CMS processing jobs on Gordon. 4k cores is larger than most CMS Tier 2's, and as big as a European Tier-1. With Bosco, overnight, Gordon became one of the largest CMS clusters in the world.
Full details will be written in a submitted paper to CHEP '13 in Amsterdam, and Bosco will be presented in a poster (and paper) as well. I hope to see you there!
(If I got any details wrong about the CMS side of this run, please let me know. I have intimate knowledge of the Gordon side, but not so much the CMS side).
